
Hyper-Threading detailně | Kapitola 5

Seznam kapitol
Původně měl název tohoto článku znít "Hyper nebo Hype?" jako reakce na uvedení nového procesoru Pentium 4 na frekvenci 3.06 GHz. Přestože všichni oslavují Hyper-Threading jako převratnou a skvělou technologii, já bych v tak pozitivním hodnocení byl o něco opatrnější. Při bližším pohledu na celou věc a pochopení základních principů zpracování instrukcí uvnitř procesoru je totiž zcela zřejmé, že i zde jsou určitá problémová místa. Chcete-li vědět, co je Hyper-Threading, které programy z něj mohou profitovat, ale i na co byste si měli dát pozor, neměl by vám tento článek uniknout.
Pentium 4
V předchozí kapitole jsem nakousnul, co se změnilo v architekturě Pentia 4. Důvod byl zcela zřejmý - bude to právě Pentium 4, které se pokusí přinutit programátory navrhovat aplikace s co možná největší mírou paralelismu, tak, aby se využila technologie Hyper-Threading a výkon tak celkově stoupl. Díky tomu se zlepší i podpora více procesorových systémů, ty totiž budou z paralelismu profitovat také.
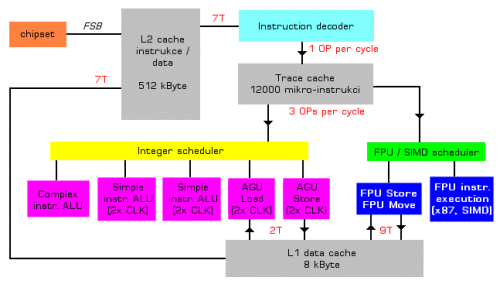
Toto je zjednodušené schéma procesoru Pentium 4, které jsem vytvořil. Sehnat nějaké přímo z Intelu se mi bohužel nepodařilo, patrně ani neexistuje.
Již na první pohled je Pentium 4 procesor o něčem jiném než Athlon. Jeho design se od ostatních procesorů kompatibilních s x86 instrukční sadou podstatně liší. První odlišností je absence instrukční cache první úrovně. Místo ní je teď až za dekodérem cache na OPs. Do ní dekodér ukládá dekódované instrukce, přičemž samotné instrukce na dekódování se bere přímo v L2 cache. Zatímco u Athlonu a jiných procesorů se instrukce dodávají přímo z dekodéru do Instruction Control Unit a následně do Schedulerů, zde tuto úlohu plní tato cache. Nazývá se Trace cache a její kapacita dnes činí 12000 OPs.
Druhou markantní odlišností je počet jednotek a netradičně i jejich frekvence. Procesor obsahuje dvě ALU jednotky pro jednoduché operace (například sčítání), které pracují na dvojnásobné frekvenci procesoru. Protože ne všechny instrukce jsou jednoduché, je zde ještě jedna ALU jednotka pro komplexní celočíselné operace. Ta pracuje "pouze" na frekvenci procesoru. K těmto třem jednotkám náleží ještě jedna AGU jednotka pro čtení a jedna pro zápis, přičemž obě pracují na dvojnásobné frekvenci procesoru.
Athlon má tři ALU jednotky pro všechny instrukce a tři AGU jednotky pro čtení i zápis.
FPU část je podobně jako u Athlonu rozdělena na subjednotky. Ty jsou tentokrát ale pouze dvě. Jedna se stará o ukládání dat a ta druhá počítá x87 a SIMD operace.
Athlon má jednu jednotku na ukládání, jednu na SIMD a sčítání x87, druhou na SIMD a násobení x87.
Již na první pohled je zřejmé, že Pentium 4 nemá tolik jednotek jako Athlon. Především pak FPU část je o hodně pomalejší než v případě Athlonu. To je logické - co se týče výpočtů instrukcí, není zde možný žádný paralelismus, není ho totiž kde provést. Naproti tomu rozdělení ALU jednotek na jednoduché a složité a jejich optimalizace není až tak špatný nápad, jednoduchých instrukcí je v běžném kódu relativně hodně. V operacích jako sčítání bude Pentium 4 nad Athlonem díky rychlejším ALU jednotkám patrně vítěžit.
Je zde ještě jeden fakt, na který se nesmí zapomínat. Tím je, že délka pipeline je oproti Athlonu dvojnásobná. Proto v ní bude spíše docházet k čekání na výsledky jiných výpočtů a horší bude také situace při špatném odhadu větvení za podmínkou. Jestliže totiž dojde k špatnému odhadu, bude nutné celou pipeline vyprázdnit a znovu naplnit daty. A protože je tak dlouhá, bude první výsledek dostupný až za 20 cyklů, nikoli za 10 jako v případě Athlonu.
Kde může Pentium 4 profitovat
Ať už z našich testů nebo testů na jiných webech (Tom´s Hardware, např.) vyplynulo, že Hyper-Threading ve většině případů nemá žádný nebo má dokonce negativní dopad na výkon. Uvažujeme-li známá fakta a princip této technologie, není to až tak velké překvapení. Pentiu 4 je již svým návrhem výpočetní části předurčeno, že možných využití Hyper-Threadingu není právě nejvíc.
Předně je třeba zmínit, že v FPU části není možné uvažovat o nějak rozsáhlém paralelismu. Není například možné počítat dvě SIMD nebo x87 instrukce najednou, jednoduše proto, protože není kde. Prakticky jediná výhoda by mohla nastat, když by jeden thread chtěl ukládat data (využít FPU Store / Move jednotku) a druhý by zároveň chtěl počítat (využít FPU provádějící samotné výpočty). Takových situací ale patrně příliš mnoho nebude.
Velice podobně vypadá situace v ALU. Zde je možné paralelizovat buďto vykonávání více jednoduchých instrukcí zároveň nebo kombinaci jedné jednoduché a jedné složité instrukce. Setkají-li se dvě složité instrukce nebo je-li požadavek na využití AGU jednotek, dojde ke konfliktu a bude nutné jeden z threadů pozastavit.
V praxi tak největší výpočetní výhody plynou ze směsice kódu SIMD / x87 a klasického x86. V takovém případě se rovnoměrně využijí jednotky FPU i ALU. Bohužel (bohudík) něco podobného je realizovatelné i na úrovni paralelizování jednoho threadu.
Paradoxně největší výhoda technologie Hyper-Threading nespočívá ve využití více jednotek najednou, ale v eliminaci čekání na data. Dva thready jsou na sobě více méně nezávislé programy. Každý využívá jiná data a tudíž i jinou oblast v paměti (proměnné se obvykle v paměti organizují přímo za sebou). Protože Pentium 4 používá prefetch mechanismus, který do cache nahrává při požadavku na data z nějaké konkrétní oblasti paměti i data umístěná v paměti hned vedle, je velice pravděpodobné, že procesor bude mít při vykonávání instrukcí příslušná data již v cache. Pokud je náhodou mít nebude, bude muset čekat klidně i desítky hodinových cyklů, než se mu je podaří z paměti získat. A hádejte, co se bude dít mezi tím. No jistě, výpočetní jednotky budou lenošit! Jestliže ale budou spuštěny dva thready současně, využije procesor čekání na data u jednoho threadu k vykonání threadu druhého. Je totiž velice nepravděpodobné, že by nastala situace, kdy budou spuštěny dva thready, které oba čekají na data z paměti (účinnost cache je běžně vysoko nad 90 procent).




