
Hyper-Threading detailně | Kapitola 2

Seznam kapitol
Původně měl název tohoto článku znít "Hyper nebo Hype?" jako reakce na uvedení nového procesoru Pentium 4 na frekvenci 3.06 GHz. Přestože všichni oslavují Hyper-Threading jako převratnou a skvělou technologii, já bych v tak pozitivním hodnocení byl o něco opatrnější. Při bližším pohledu na celou věc a pochopení základních principů zpracování instrukcí uvnitř procesoru je totiž zcela zřejmé, že i zde jsou určitá problémová místa. Chcete-li vědět, co je Hyper-Threading, které programy z něj mohou profitovat, ale i na co byste si měli dát pozor, neměl by vám tento článek uniknout.
Procesor uvnitř
Protože již víte, co jsou to instrukce a thready, je nyní možné přistoupit k vlastní charakteristice toho, jak procesor tyto instrukce zpracovává.
Nejdříve blokové schéma - procesor AMD Athlon:
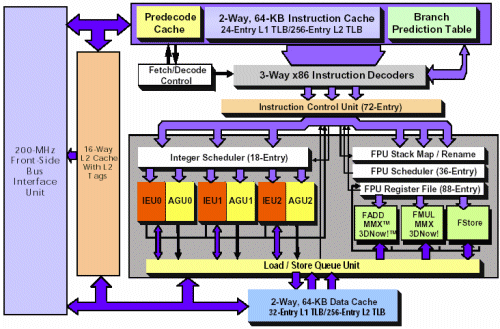
Na první pohled velmi složité, že? Po pravdě toto schéma je ještě velmi zjednodušené. Nyní k jednotlivým částem. Procesor na to, aby mohl počítat, musí mít nějaké instrukce a data. Tyto informace získá z paměti počítače. Paměť je připojena do čipové sady a čipová sada pak spojena pomocí sběrnice zvané Front Side Bus (na obrázku vlevo) do procesoru.
Z Front Side Bus putují data obvykle do velmi rychlé paměti cache. Ta se člení na několik úrovní, čím vyšší úroveň, tím má obvykle cache větší kapacitu, je ale také pomalejší. Běžné procesory mají dnes obvykle dvě úrovně, verze pro servery a pracovní stanice pak často tři. Třetí a druhá úroveň jsou většinou unifikované, ukládají se do ní instrukce i data. První úroveň je již rozdělená na cache pro instrukce a pro data. Důvodem je mechanismus předdekódování instrukcí (o tom se zmíním dále).
Data na chvíli pominu a budu se věnovat instrukcím. Jakmile instrukce dorazí do cache první úrovně, putují dále do instrukčního dekodéru. Ten převádí instrukce sad x86, x87 atd. na vnitřní instrukce procesoru zvané OPs. Výpočetní části nerozumí instrukcím sady x86, pouze těmto OPs. Jsou to vlastně mikro-instukce pevné délky (x86 může být různě veliké), které určují přesné chování výpočetní jednotky. Jedna instrukce x86 může být převedena na jednu až několik desítek OPs, podle složitosti operace. Například takové zvýšení hodnoty v registru (EAX, EBX...) o jedničku je mnohem jednodušší operací než celočíselné dělení.
Insider: odhad větvení kóduDekodér při své činnosti využívá předdekódování a Branch Prediction Table. O co jde? V programu jsou často podmínkové skoky. Když je výsledek nějaké operace takový, provede se jeden kód, pokud onaký, provede se jiný kód. Protože instrukce jsou vnitřně v procesoru vykonávány v jiném pořadí, než jsou v programu za sebou (tzv. out-of-order), je možné obejít čekání na data, urychlit výpočet spočtením subvýpočtů naráz (1+2+3+4 bude trvat dva početní cykly, protože se nejprve sečte současně 1+2 a 3+4 a potom výsledky - tím se ušetří jeden cyklus) nebo dokonce začít počítat kód, který následuje až po podmínkovém skoku. Procesor odhadne, jaký asi bude výsledek podmínky ještě před tím, než jí skutečně vypočte, a rovnou začne počítat tu větev kódu, o které si myslí, že je ta správná. Aby mohl tyto odhady provádět, musí průběžně sledovat tok instrukcí a odhadnout tak, jak se bude program dále vyvíjet. Sledování toku instrukcí se provádí tak, že instrukce jsou dekódovány, ale nejsou tvořeny OPs, ale záznamy v Branch Prediction Table. Tomu se říká předdekódování. |
OPs dále putují do Instruction Control Unit, kde jich v případě Athlonu může být až 72. Toto je jakási rozřazovací jednotka, která určuje pořadí vykonávání OPs za sebou a jejich přidělení mezi ALU a FPU část. ALU je zkratka pro Arithmetic Logic Unit, což jsou jednotky zabývající se výpočty s celými čísly. FPU naproti tomu znamená Floating Point Unit a jsou to jednotky počítající s desetinnými čísly, popřípadě se SIMD instrukcemi (MMX, 3Dnow!, SSE atd.).
Z Instruction Control Unit jsou OPs zaslány do Integer Scheduler (obsluhuje jednotky ALU) nebo do FPU Scheduler (obsluhuje jednotky FPU). Scheduler se stará již o samotné přidělování OPs jednotlivým výpočetním jednotkám. OPs jsou pokud možno přidělovány tak, aby se maximálně využil potenciál jednotlivých jednotek, tj. aby jich v jeden okamžik pracovalo co nejvíce.
Jednotlivé výpočetní jednotky již provedou požadované operace přikázané jednotlivými OPs. Při tom přistupují do datové cache první úrovně, odkud si berou (a kam ukládají) data.




