
Hyper-Threading detailně | Kapitola 3

Seznam kapitol
Původně měl název tohoto článku znít "Hyper nebo Hype?" jako reakce na uvedení nového procesoru Pentium 4 na frekvenci 3.06 GHz. Přestože všichni oslavují Hyper-Threading jako převratnou a skvělou technologii, já bych v tak pozitivním hodnocení byl o něco opatrnější. Při bližším pohledu na celou věc a pochopení základních principů zpracování instrukcí uvnitř procesoru je totiž zcela zřejmé, že i zde jsou určitá problémová místa. Chcete-li vědět, co je Hyper-Threading, které programy z něj mohou profitovat, ale i na co byste si měli dát pozor, neměl by vám tento článek uniknout.
Jeden procesor = jeden thread
Z již zmíněných informací vyplývá jeden poměrně zásadní fakt - jeden procesor zpracovává v jeden okamžik pouze jeden thread. Proč? Instrukční dekodér dekóduje instrukce v pořadí, jak jdou za sebou, tj. v takovém pořadí, které je určeno již samotným programem. Protože dekodér nesmí ztratit přehled o tom, které další instrukce má dekódovat, musí si vést evidenci o tom, která instrukce následuje kterou. A to je v praxi možné vysledovat pouze v rámci jednoho threadu, kde je chod instrukcí po sobě určen tím, jak jsou v programu napsány. Kdyby se do procesoru řítily instrukce několika threadů naráz, dekodér by nepoznal, která instrukce následuje kterou a pak by třeba dekódoval něco, co neměl.
Správa zpracování jednotlivých threadů se provádí na úrovni operačního systému. Ten rozhoduje o tom, který thread bude následovat který, co se provede přednostně atp. Starší systémy jako DOS nebyly multitaskingové, v nich nebyl až takový problém nakládat s thready. Vždy tam totiž platilo, že aktuálně je spuštěný pouze jeden program. Moderní systémy jako Windows jsou samozřejmě multitaskingové, to znamená, v jeden okamžik pod nimi můžou být spuštěny až desítky threadů. Protože procesor je schopen počítat v jednom okamžiku pouze s jedním threadem, musí se Windows postarat o to, který thread dostane přednost před kterým.
Víceprocesorové systémy
Situace správy threadů v multitaskingovém prostředí je značně zjednodušena přítomností více procesorů. Jestliže je každý z nich schopen provádět jeden thread, jsou dva schopné vykonávat thready dva. Pokud jsou výsledky výpočtů v jednotlivých threadech na sobě nezávislé, není problém přiřadit každému procesoru jeden thread.
V praxi na sobě nezávislých threadů v rámci jednoho programu až tak moc není, většinou se spíše využívá toho, že například spuštění programu vyvolá spuštění části Windows zodpovědné za zobrazení programu na obrazovku. V takovém případě jsou najednou spuštěné programy dva - volaný program a část Windows zodpovědná za zobrazení. Každý z těchto programů tvoří jeden thread, proto je možné je přidělit více procesorům a celou operaci tak urychlit.
Jiným příkladem využití více procesorů jsou náročné výpočty, například vyhlazování hran v obrázcích nebo práce v AutoCADu. To jsou v zásadě stále stejné činnosti, pouze je nutné je opakovat pro velké množství dat (u vyhlazování obrázků pro každý pixel, v AutoCADu pro každou souřadnici objektu). Jestliže je program takto stereotypní, může buďto profitovat ze SIMD instrukcí nebo využít více threadů a každý spustit na samostatném procesoru. V našem příkladu s vyhlazováním obrázků program vyvolá dva thready, kde jeden bude zpracovávat jednu množinu pixelů a druhý množinu jinou. Výpočet se tak značně urychlí.
Využití stávajících jednotek - mizivé!
Podívejme se nyní opět na blokové schéma procesoru Athlon.
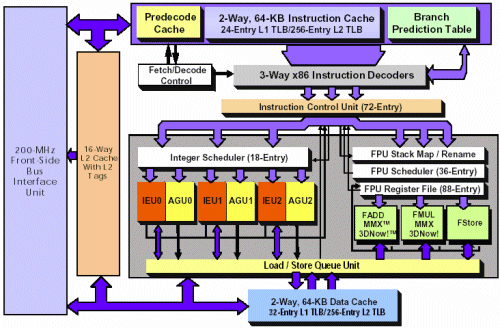
Co se týče výpočetních jednotek, je Athlon vybaven třemi jednotkami ALU (zde označené IEU - Integer Execution Unit), třemi AGU - Adress Generation Unit (ty se starají o výpočet adres v paměti) a třemi FPU jednotkami. Vlastně bych měl spíše říct jednou jednotkou FPU. Vtip je totiž v tom, že Athlon má tři (sub)jednotky FPU, z nichž každá je schopná vykonávat pouze některé operace. Jedna umí sčítání a SIMD operace, další násobení a SIMD operace. Poslední umí pouze ukládat data (všimněte si šipek proudění dat do Load / Store Queue Unit napojenou na datovou cache). Z toho plyne, že v závislosti na posloupnosti instrukcí (OPs) jsou v chodu jedna až tři jednotky za hodinový cyklus.
Sestrojit dvě nebo tři plnohodnotné FPU jednotky schopné zpracovat všechny instrukce by bylo výrobně příliš nákladné a výkon by patrně nebyl o moc vyšší. Důvodem je fakt, že instrukce se mezi sebou poměrně často střídají, navíc díky FPU Scheduleru je často možné je seřadit takovým způsobem, že se výpočetní jednotky využijí, jak jen to jde.
Přes všechny pomocné systémy jako odhad větvení za podmínkou a paralelismus zpracování díky Schedulerům jsou situace, kdy procesor zahálí. Uvést několik příkladů je vcelku jednoduché:
- program sestává pouze ze specifických instrukcí - když by například všechny instrukce směřovaly do jednotky sčítání desetinných čísel, všechny ostatní budou v době výpočtu lenošit.
- je prováděn takový kód, který nelze paralelizovat (výpočty jsou závislé na výsledcích jiných výpočtů) - v takovém případě je využita jen jedna jednotka, další výpočty je možné provádět až poté, co byly provedeny výpočty předchozí. Ostatní jednotky v tom případě opět lenoší.
- program počítá s velkými datovými bloky - v takovém případě se často stává, že výpočetní jednotky musí čekat na nové instrukce nebo data, která se ještě "courají" v oblasti FSB. V tomto případě lenoší jednotky úplně všechny, nemají totiž co počítat.
Problém neschopnosti paralelizovat kód je také hlavním důvodem, proč jsou procesory s delší pipeline na stejné frekvenci pomalejší než procesory s pipeline kratší. Jestliže je jeden výpočet závislý na výsledku jiného, není možné tento provést, dokud neskončí ten předchozí. V případě dlouhých pipeline (například ta u Pentia 4 má 20 stupňů) bude trvat výrazně více cyklů, než se provede výpočet jednoho úkolu. A až teprve po skončení tohoto výpočtu je možné zahájit výpočet jiný. Ve zpracování tak vzniknou "prázdná místa", kdy část výpočetní jednotky nemůže počítat, protože potřebuje znát výsledek předchozí úlohy. Výsledný efekt je pak takový jako kdyby procesor pracoval na nižší frekvenci.
Ze všech těchto příkladů je vidět, že průměrné využití všech jednotek současně je mizivé, odhadem se jedná o nějakých 30%.




