
Nvidia Fermi - Analýza nové generace GPU | Kapitola 5

Seznam kapitol
Nové Radeony už mají své uvedení za námi, na Nvidii jsme si museli chvíli počkat. Rok jsme hovořili o GT300, jež vzalo za své a místo toho se objevilo kódové označení Fermi. I když vám dnes ještě kartu fyzicky neukážeme, dozvíte se o jádru téměř vše. Prohlédneme si změny vůči architektuře G200 a zaspekulujeme o parametrech karty.
V této kapitole si představíme další novinky v jádru Fermi, které stojí za pozornost. Podíváme se na novou hierarchii pamětí cache, implementaci PTX rozšíření, a v závěru také na paměťový subsystém a novinky v práci s jádry aplikací.
Paměť cache
Jedna ze zásadních novinek, jež také přibližuje Fermi k CPU, je osazení čipu vlastní pamětí cache. U jádra G200 měl každý SM blok pro všechna jádra k dispozici 16KB paměti. Zaprvé byla kapacita nedostatečná, a za druhé šlo spíše o sdílenou programovatelnou paměť, než o opravdovou cache. NVIDIA tedy do jádra Fermi cache přidala. Celý čip má k dispozici 1MB cache, kdy každý SM blok má k dispozici pro všechna jádra 64KB. Tu může programátor rozdělit na dva bloky, 48KB a 16KB. Kvůli kompatibilitě se starými CUDA aplikacemi, je možné přiřadit právě oněch 16KB a aplikace běží stejně jako na G200. Novějším programům je možné přidělit více, a to významně pomůže v efektivitě.
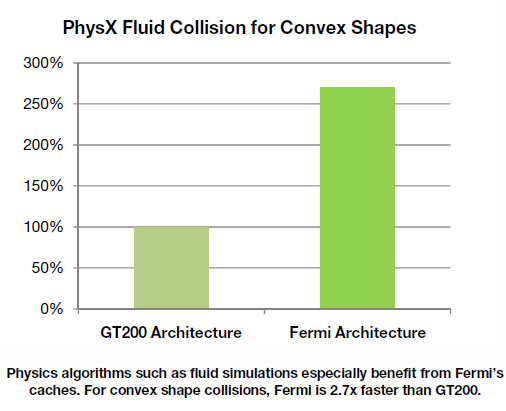
Aby se zvýšil výkon operací s hlavní pamětí (frame-bufferem) byla do jádra přidána ještě sdílená L2 cache o kapacitě 768KB. Tím byly základní operace při čtení a zápisu do paměti zrychleny až dvacetkrát. Nárůst výkonu v PhysX demu po přidání obou druhů cache do jádra ukazuje obrázek. Fermi podává téměř 2,5 x vyšší výkon. Právě toto vylepšení bude mít zcela jistě největší vliv na hry.
Parallel Thread Execution ISA
Rozšíření PTX se dočkalo druhé revize, jde o low-level virtuální stroj (GPU). Základní instrukční sada se dočkala rozšíření o nativní podporu OpenCL a DirectCompute na úrovni instrukční sady PTX. Mezi hardwarem a aplikací je stále ale vrstva ovladače, tedy nejdou o stoprocentní low-level virtualizaci. Ke zjednodušení programování v C++ byla také změněna struktura adresního prostoru pamětí karty. U G200 se muselo použití každé z pamětí přesně určit a aplikaci nasměrovat, což bylo mnohdy nepřehledné pro programátora. Fermi má unifikovaný adresní prostor, umístění v jednotlivých částech paměti se označuje pouze hodnotou identifikátoru. Také adresace se proti G200 změnila z 32-bitové na 64-bitovou, aby bylo možné adresovat více než 4 GB paměti u nejvyšších modelů. V této chvíli umí jádro teoreticky obsloužit až 1TB paměti, což bude asi navěky stačit.
Podpora ECC a výkon paměťových operací
Podpora kontroly dat proudících do pamětí a jejich integrity je v profesionální sféře klíčová. Z tohoto důvodu se právě Tesly mnoho neuplatnila, a zisky z tohoto segmentu hovoří za vše. Vzhledem k celému obratu firmy jde o zanedbatelné jedno procento. S Fermi se to má změnit, a GPU Computing by měl raketově nastartovat. No uvidíme. To ovšem nic nemění na faktu, že Fermi má nativní podporu pro ECC paměti a profesionální GPU Computing karty budou osazeny ECC moduly. Uplatnění v HPC aplikacích nic nebrání.

Díky přidaným pamětem cache, a více jednotkám je výkon v základních atomických operacích (add, min, max, swap) vyšší o 7 - 20 procent.
GigaThread a 10x rychlejší Context switching
Architektura Fermi disponuje ještě další novinkou. To je dvouvrstvý Scheduler, který na úrovni čipu rozděluje úkoly SM blokům. V nichž si pak úlohy koordinuje již vlastní Warp Scheduler, a ten nadřazený se může věnovat jiným úlohám. S tím přichází i desetkrát vyšší rychlost přepínaní aktivních úloh 3D/CUDA. Jak už jsem řekl někde v první polovině článku, typický příklad je PhysX ve hrách. V tomto scénáři se musí grafika "střídat" ve vykreslování scéna a počítání PhysX efektů, u Fermi je evidentně mnohem efektivnější a výkonnější.
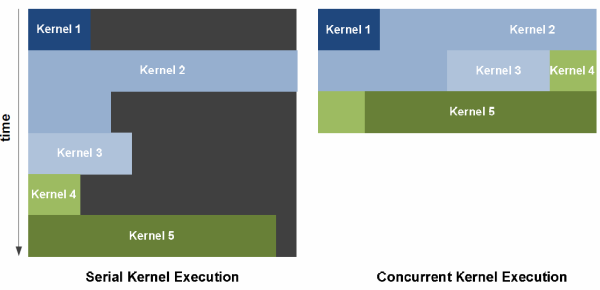
Posledním vylepšením jež zmíním, je možnost současného běhu dvou a více jader programů (kernel). U G80/G200 bylo možné spustit pouze jedno jediné jádro, což v některých situacích bránilo využití dalších jednotek. U architektury Fermi je možné spustit výkonných jader programů více (až 16), nový GigaThread engine je rozmisťuje po volných SM blocích efektivněji.
Nexus pro Visual Studio
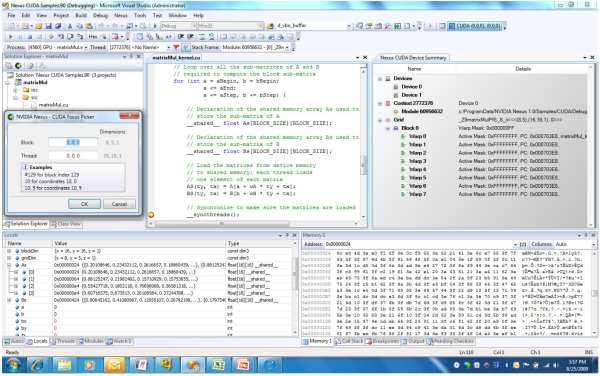
Zcela na závěr této kapitoly se podívejme na zajímavý modul pro Visual Studio - Nexus. Díky němu lze psát a ladit programy pro GPU (CUDA) stejně jako jste zvyklí pro klasické CPU. S tímto rozšířením prakticky nepoznáte rozdíl, zdali píšete pro CPU nebo GPU. Kompilace pak samozřejmě proběhne dle nastaveného výstupu. S tímhle by se skutečně programování pro GPU mohlo hnout z místa a rozšířit více i do oblastí, kde se dosud neetablovalo.




