Nvidia Fermi - Analýza nové generace GPU | Kapitola 3

Seznam kapitol
Nové Radeony už mají své uvedení za námi, na Nvidii jsme si museli chvíli počkat. Rok jsme hovořili o GT300, jež vzalo za své a místo toho se objevilo kódové označení Fermi. I když vám dnes ještě kartu fyzicky neukážeme, dozvíte se o jádru téměř vše. Prohlédneme si změny vůči architektuře G200 a zaspekulujeme o parametrech karty.
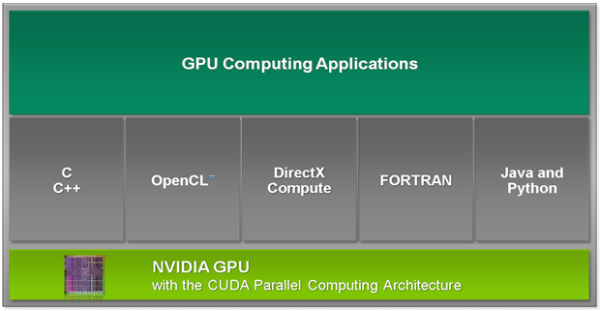
CUDA není jen programovací jazyk, jak se mnozí mylně domnívají, ale název celého konceptu (řekněme architektury). Pod NVIDIA CUDA patří DirectCompute pod DX11, OpenCL, C, C++, Fortran. Prostě všechny prostředí a rozhraní, která mohou na GPU běžet. CUDA je ono rozhraní, díky němuž lze takto napsané a zkompilované programy na GPU vykonat. Na internetu se dokonce objevily spekulace, že jádro Fermi bude umět spustit aplikaci napsanou v C++ a zkompilovanou pro x86 CPU, to je ovšem hloupost. Tuhle věc možná bude umět Intel Larrabee, ovšem nikoliv GPU od NVIDIA. Pro GPU je nutné vždy program zkompilovat v příslušném CUDA kompatibilním kompileru, nebo ji spustit například ve virtuálním režimu.
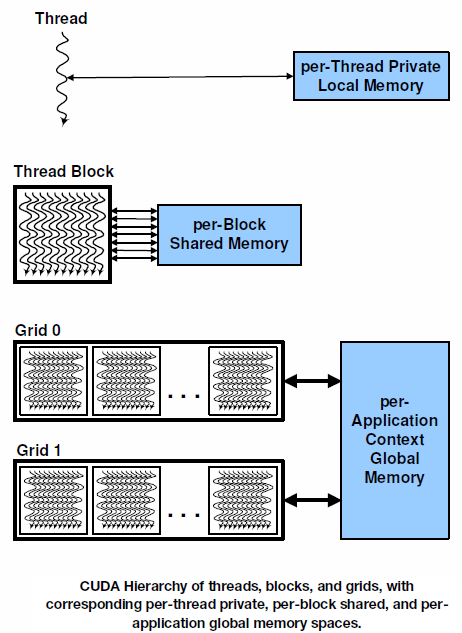
Výkonné jádro programu (kernel) je realizováno několika paralelními vlákny (thready). Programátor sám, nebo kompilátor uspořádá tato vlákna do bloků vláken (threads block) a ty pak do vláknové mřížky (thread grid). GPU si pak rozloží jádro programu do mřížky paralelních bloků. Každé vlákno v bloku bude spuštěno jako součást jádra aplikace, a obdrží unikátní identifikátor (ID), který popisuje z jakého je bloku, k jakému programu patří, jaký je jeho zdroj a další informace. Celý blok vláken může obsahovat až 1536 samostatných vláken, a celému bloku je také přidělen identifikátor (ID) ze kterého je gridu. Celý tento grid je vykonáván jediným jádrem programu a výsledek může být zapsán a čten z hlavní paměti.
V architektuře CUDA je každému vláknu, bloku i gridu přidělena část paměti, pro odkládání registrů, volání funkcí a poměných. Jednotlivá vlákna mají svou vlastní přidělenou část paměti, bloky a gridy se musí spokojit se sdíleným prostorem. Posloupnost průchodu vláken kopíruje rozložení procesorů v samotném GPU jádru. Celé GPU může vykonat najednou několik celých gridů vláken, SM jednotka umí pracovat s bloky vláken a samotný CUDA procesor zpracovává jednotlivá vlákna. SM jednotka (v jádru Fermi jich je šestnáct) dokáže zpracovat vlákna po skupinách. Skupina 32 vláken se nazývá Warp. V novém jádru jsou Warp Shedulery dva, G200 mělo v SM bloku jen jeden.
Kam směřuje NVIDIA?
Na prvním místě jednoznačně nyní stojí GPU Computing, a někde vzadu se krčí herní výkon. NVIDIA prý dokonce dala vyšší prioritu produktům jako Tegra, před desktopovými grafikami. Ostatně jde asi o správnou cestu do budoucnosti, i když desktop PC ještě dlouho nezanikne, tržby z tohoto segmentu jsou rok od roku nižší. Zájem majoritního podílu zákazníků se upírá právě k miniaturním zařízením, než "bedně" pod stolem.
Také grafická karta určená pro GPU Computing (dnes řada Tesla) stojí i několikanásobně více než běžná karta osazená stejným jádrem, tedy na ní výrobce vydělá mnohem více. Jeden takový superpočítač osazený GPU NVIDIA vytvoří firmě větší zisk než celý český předvánoční trh, tedy je také zaměření na tuto oblast lukrativnější. Další důvod je také zřejmý, NVIDIA chce prostě Intelu dokázat, že CPU je skutečně "mrtvé" jak už několikrát v minulosti prohlašovala. Tím důkazem má být architektura Fermi ..